Thanks to the marvelous efforts of folks like Jessica Flake and Eiko Fried, I don't need to convince anyone reading this that we have to take the validation process for psychological self-report scales seriously*. There are many ways to validate such measures, which have been expertly detailed elsewhere. In this post, I will focus on an oft neglected form of scale validation, which I term contingent validity --- which reflects whether a scale's criterion validity is contingent upon theoretically-appropriate situational conditions.
I've been on sabbatical and part of my scholarly leave activities have been to read older texts on the topics I study. One book from the early 1980s on the measurement of aggression repeatedly cited examples of various scale validation attempts to centered on the use of experimental manipulations to either (A) impact the scale's score directly or (B) moderate the link between the scale's score and a criterion measure. The former should be applied to state scales that assess momentary and transient constructs, whereas the latter should be applied to trait scales that measure durable constructs and it will remain our focus here for this introduction to contingent validity**.
Some examples I read were:
Example 1 --- To validate a Hostility Scale, a group of investigators tested whether people who scored higher on this hostility measure would say more and more hostile words when others reinforced (versus punished) them for using such words. (IV: Hostility Scale score, DV: hostile word count, Moderator: reinforcement vs. punishment).
Example 2 --- For a Different Hostility Scale, investigators tested whether people who scored higher on this hostility measure would identify with more hostile traits after they were exposed to an arousing (versus non-arousing) stimulus. (IV: Different Hostility Scale score, DV: hostile trait identification, Moderator: arousal vs. non-arousal).
In my reading of texts from around this same time, it became clear that using experimental manipulations to examine the construct validity of scales was commonplace. Such practices are now mostly absent from the literature as far as I can tell.
The use of these manipulations was clearly motivated by the investigators' desire to test whether the scale they developed would perform as their theories suggested it should (i.e., predict more hostile behavior when reinforced or sympathetically aroused). Though these validation studies preceded the person-situation debate, they were driven by the logic that this controversy eventually bestowed (i.e., that personality -- and valid measures thereof -- are best understand in the context of the environment).
*My own efforts to convince folks about the dire need to better validate our experimental manipulations have been met with less enthusiasm and success.
**The authors of those scales from the mid-20th century didn't seem to make this distinction, often failing to articulate whether a given measure was of a trait or a state, and thus they often examined the direct and moderating impacts of experimental manipulations interchangeably, something that they shouldn't have done.
I've been on sabbatical and part of my scholarly leave activities have been to read older texts on the topics I study. One book from the early 1980s on the measurement of aggression repeatedly cited examples of various scale validation attempts to centered on the use of experimental manipulations to either (A) impact the scale's score directly or (B) moderate the link between the scale's score and a criterion measure. The former should be applied to state scales that assess momentary and transient constructs, whereas the latter should be applied to trait scales that measure durable constructs and it will remain our focus here for this introduction to contingent validity**.
Some examples I read were:
Example 1 --- To validate a Hostility Scale, a group of investigators tested whether people who scored higher on this hostility measure would say more and more hostile words when others reinforced (versus punished) them for using such words. (IV: Hostility Scale score, DV: hostile word count, Moderator: reinforcement vs. punishment).
Example 2 --- For a Different Hostility Scale, investigators tested whether people who scored higher on this hostility measure would identify with more hostile traits after they were exposed to an arousing (versus non-arousing) stimulus. (IV: Different Hostility Scale score, DV: hostile trait identification, Moderator: arousal vs. non-arousal).
In my reading of texts from around this same time, it became clear that using experimental manipulations to examine the construct validity of scales was commonplace. Such practices are now mostly absent from the literature as far as I can tell.
The use of these manipulations was clearly motivated by the investigators' desire to test whether the scale they developed would perform as their theories suggested it should (i.e., predict more hostile behavior when reinforced or sympathetically aroused). Though these validation studies preceded the person-situation debate, they were driven by the logic that this controversy eventually bestowed (i.e., that personality -- and valid measures thereof -- are best understand in the context of the environment).
*My own efforts to convince folks about the dire need to better validate our experimental manipulations have been met with less enthusiasm and success.
**The authors of those scales from the mid-20th century didn't seem to make this distinction, often failing to articulate whether a given measure was of a trait or a state, and thus they often examined the direct and moderating impacts of experimental manipulations interchangeably, something that they shouldn't have done.
Cognitive-Affective Processing System (CAPS): Personality As Situational Contingencies
Personality is a bit of a conundrum in that it is both stable across situations but also dramatically affects how you respond to a given situation. My favorite graduate seminar was on personality psychology and focused heavily on this issue. One of the best theories we discussed was Mischel & Shoda's Cognitive-Affective Processing System (CAPS) Theory. This theory arose out of the ashes of the person-situation debate and has numerous elements that explain how personality and situations interact to explain human behavior. My favorite of these proposed theoretical elements is circled in red below, the if-then profiles that arise as a product of the CAPS. These if-then profiles reflect 'distinctive and stable' patterns of behavioral responses to specific situations. For example, some people tend to respond to situations where they feel insulted with anger and aggression whereas others would tend to respond with fear and avoidance. Some people tend to respond to others' need for help with confidence and action, whereas others tend to respond with uncertainty and inaction. It is these if-then profiles that can be leveraged to examine a scale's contingent validity.
Personality is a bit of a conundrum in that it is both stable across situations but also dramatically affects how you respond to a given situation. My favorite graduate seminar was on personality psychology and focused heavily on this issue. One of the best theories we discussed was Mischel & Shoda's Cognitive-Affective Processing System (CAPS) Theory. This theory arose out of the ashes of the person-situation debate and has numerous elements that explain how personality and situations interact to explain human behavior. My favorite of these proposed theoretical elements is circled in red below, the if-then profiles that arise as a product of the CAPS. These if-then profiles reflect 'distinctive and stable' patterns of behavioral responses to specific situations. For example, some people tend to respond to situations where they feel insulted with anger and aggression whereas others would tend to respond with fear and avoidance. Some people tend to respond to others' need for help with confidence and action, whereas others tend to respond with uncertainty and inaction. It is these if-then profiles that can be leveraged to examine a scale's contingent validity.
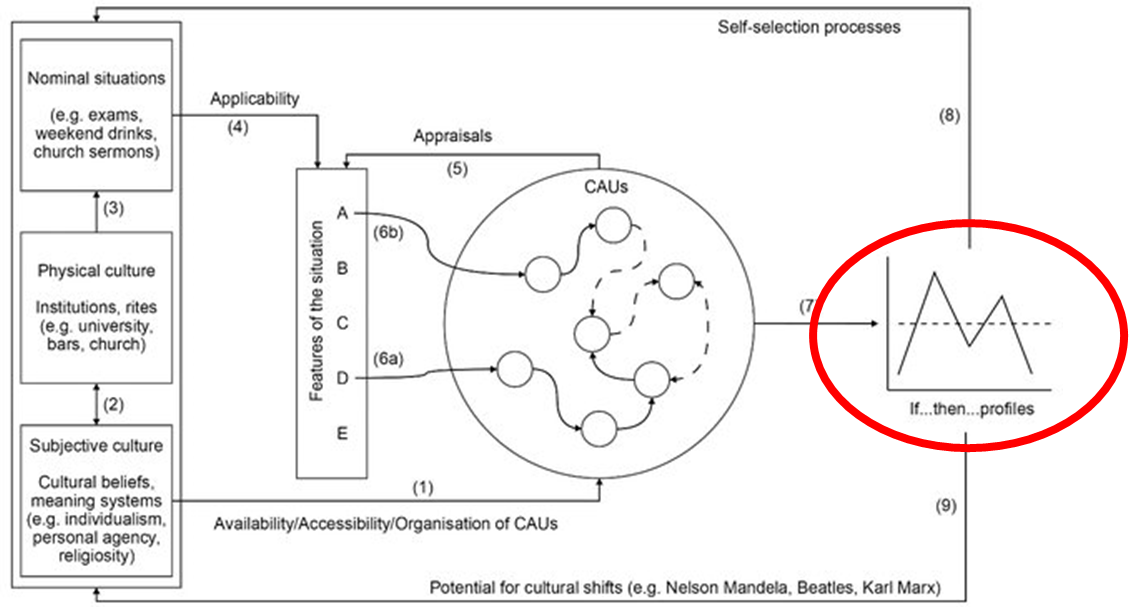
Adapted from Mendoza-Denton & Mischel (2010)
Contingent Validity
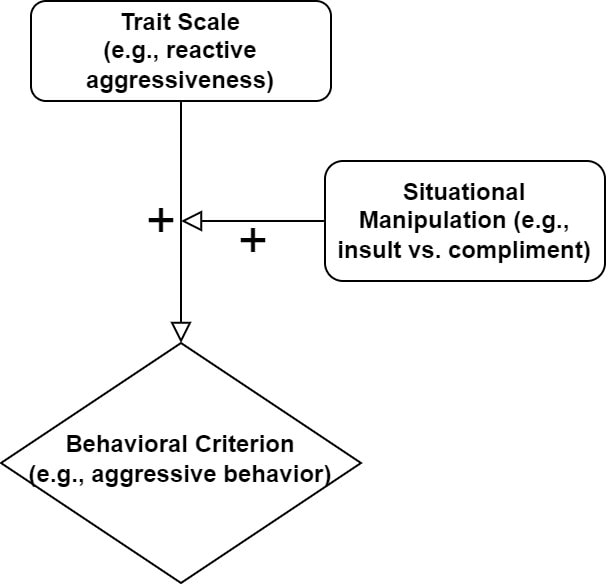
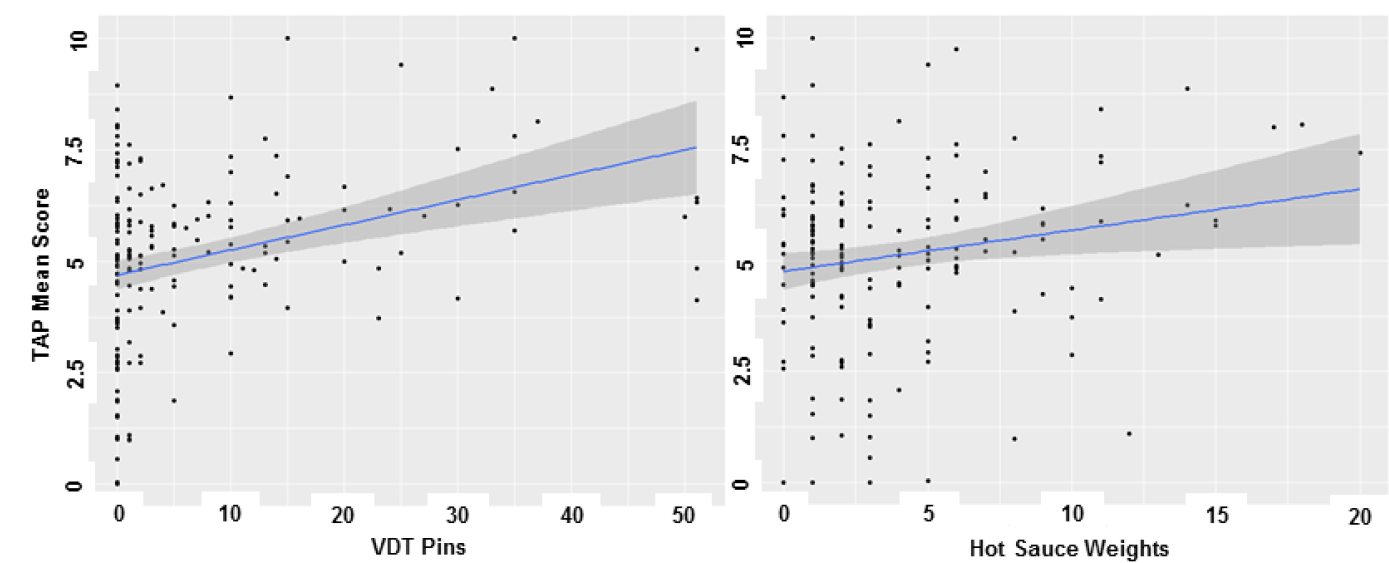
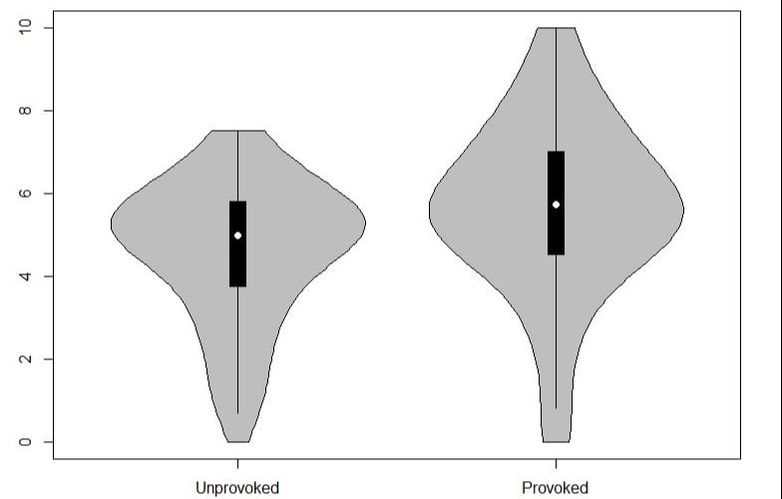
To understand contingent validity, we must understand one of its key ingredients -- criterion validity. Criterion validity, which can be assessed in a predictive or concurrent manner, refers to whether a given scale's score is associated with a theoretically-appropriate outcome (usually a behavioral outcome). For instance, a reactive aggressiveness scale with sufficient criterion validity will produce scores that are positively associated with the number of, say, violent crimes someone has committed or will commit.
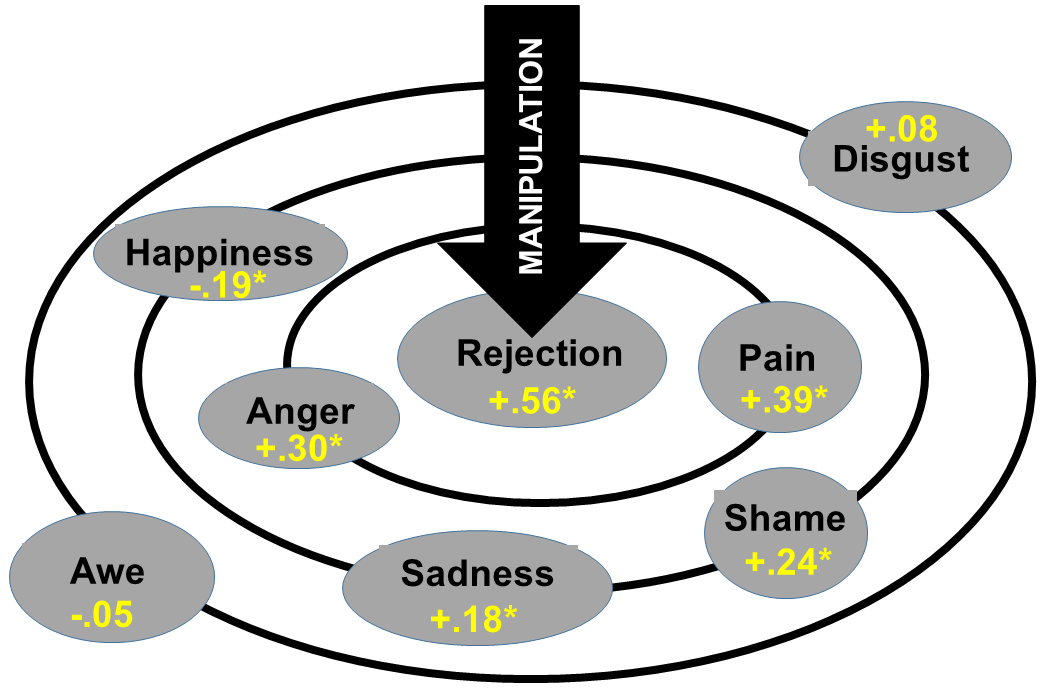
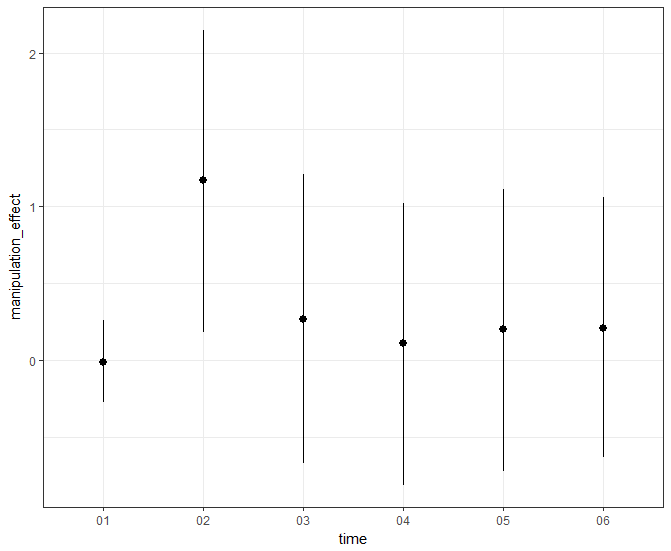
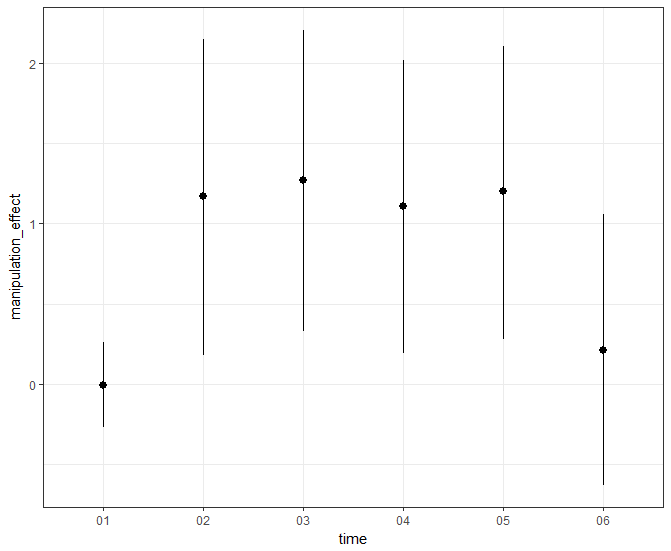
Given that such behavioral manifestations of personality should often be contingent on the situation (e.g., the if-then profiles articulated in the CAPS theory), then a valid measure should reflect such situational contingency (i.e., should exhibit evidence of contingent validity). This should be especially true for traits that are especially situationally contingent in their theoretical definitions. Reactive aggression, for example, is characterized by a tendency to respond to provocations with impulsive levels of aggression. As such, the link between scores on a valid reactive aggressiveness scale and violent behavior should be amplified by situations characterized by interpersonal provocation. This can be tested in a simple moderation model depicted below.
To understand contingent validity, we must understand one of its key ingredients -- criterion validity. Criterion validity, which can be assessed in a predictive or concurrent manner, refers to whether a given scale's score is associated with a theoretically-appropriate outcome (usually a behavioral outcome). For instance, a reactive aggressiveness scale with sufficient criterion validity will produce scores that are positively associated with the number of, say, violent crimes someone has committed or will commit.
Given that such behavioral manifestations of personality should often be contingent on the situation (e.g., the if-then profiles articulated in the CAPS theory), then a valid measure should reflect such situational contingency (i.e., should exhibit evidence of contingent validity). This should be especially true for traits that are especially situationally contingent in their theoretical definitions. Reactive aggression, for example, is characterized by a tendency to respond to provocations with impulsive levels of aggression. As such, the link between scores on a valid reactive aggressiveness scale and violent behavior should be amplified by situations characterized by interpersonal provocation. This can be tested in a simple moderation model depicted below.
Future Directions
I hope for a return of the field to the practices of contingent validity. I'd like nothing more than to review and read scale validation papers that place situational variables in a key role. I think a lot of this work is going on, but under the auspices of substantive hypothesis testing instead of validation efforts. I hope such studies will grow in quantity and quality and be given their proper home in the realm of psychometrics.
I think experimental manipulations are often ignored or actively avoided by personality and other assessment-oriented psychologists. Perhaps because they are perceived as irrelevant to scale validation (a perception I hope to have combated here), or perhaps because of their association with Questionable Manipulation Practices (QMAPS), or maybe other reasons. But at the end of the day, measurement and manipulation skills should be in the toolkit of every psychological researchers, especially those
Just as personality and clinical folks have admonished experimental psychologists about their lacking psychometric skills, I hope us experimental folks will respectfully advocate for assessment-oriented folks to adopt experimental manipulation approaches as well.
That said, there is no need to rely purely on experimental manipulations to examine contingent validity. One could easily examine situational contingency using correlational approaches. One could easily test whether a scale's criterion validity is altered among people who tend to experience more or less of the situation (cross-sectional approach) or whether such criterion validity fluctuates within-participants as a function of the given situation's presence or absence over time (repeated-measures approach).
Yet given the many advantages of well-validated manipulations, the experimental approach deserves a prominent role in the estimation of contingent validity. I hope to see such a trend soon.
I hope for a return of the field to the practices of contingent validity. I'd like nothing more than to review and read scale validation papers that place situational variables in a key role. I think a lot of this work is going on, but under the auspices of substantive hypothesis testing instead of validation efforts. I hope such studies will grow in quantity and quality and be given their proper home in the realm of psychometrics.
I think experimental manipulations are often ignored or actively avoided by personality and other assessment-oriented psychologists. Perhaps because they are perceived as irrelevant to scale validation (a perception I hope to have combated here), or perhaps because of their association with Questionable Manipulation Practices (QMAPS), or maybe other reasons. But at the end of the day, measurement and manipulation skills should be in the toolkit of every psychological researchers, especially those
Just as personality and clinical folks have admonished experimental psychologists about their lacking psychometric skills, I hope us experimental folks will respectfully advocate for assessment-oriented folks to adopt experimental manipulation approaches as well.
That said, there is no need to rely purely on experimental manipulations to examine contingent validity. One could easily examine situational contingency using correlational approaches. One could easily test whether a scale's criterion validity is altered among people who tend to experience more or less of the situation (cross-sectional approach) or whether such criterion validity fluctuates within-participants as a function of the given situation's presence or absence over time (repeated-measures approach).
Yet given the many advantages of well-validated manipulations, the experimental approach deserves a prominent role in the estimation of contingent validity. I hope to see such a trend soon.














 RSS Feed
RSS Feed
