Recently, I've been thinking about Questionable MAnipulation Practices - the choices that experimental psychologists often make about our experimental manipulations that are often unjustified or not portrayed in a transparent fashion. Beyond this, there is another potentially problematic aspect of experimental psychology that continues to ensorcell me: our validation of experimental manipulations of psychological constructs.
The Potential Problems
Experimental psychologists receive remarkable training in how to develop and implement valid experimental manipulations of psychological constructs. Methods classes teach us how to design and execute manipulations that achieve internal validity by focusing on aspects such as avoiding:
-biases in the selection and attrition of participants
-experimenter effects
-demand characteristics and participant suspicion
-confounds between conditions
However, such training sometimes skips over a critical interstitial phase that resides between development and implementation: validation.
-biases in the selection and attrition of participants
-experimenter effects
-demand characteristics and participant suspicion
-confounds between conditions
However, such training sometimes skips over a critical interstitial phase that resides between development and implementation: validation.
We are often taught that if we develop a precise manipulation and implement it flawlessly, it will be valid. But how do we know that it is valid? Here's the answer: if you skip the validation phase, you don't know if (and can't assert that) your manipulation is valid. Without empirical evidence of the validity of your manipulation, there is no scientific basis on which you can assert its validity.
A potential reason that psychology is in a so-called 'replication crisis' may be because we didn't spend sufficient resources, time, and energy on this validation phase of our manipulations.
Yet many experimental psychologists might disagree with me --- arguing that experimental manipulations are indeed validated. However, the current approach to the validation of experimental manipulations is undermined by several key issues:
1. An excessive or sole emphasis on face validity.
2. Use of unvalidated manipulation checks.
3. Assuming a manipulation is valid because it had the predicted effect on an outcome of interest.
***If you want more detail on these first three instances and my arguments for why they aren't good validation metrics, check out my previous blogpost on the topic.***
4. Using under-powered (and often unpublished) pilot studies. Many researchers do want to make sure their manipulations 'work' and to determine whether this is the case, they'll run pilot studies. These pilot studies are run-throughs of the manipulation alongside a manipulation check. They're often conducted with small samples in order to reserve greater resources for the real study of interest. The resulting pilot data often remain in laboratory file drawers, away from the scrutiny of peer review. Basing future experimental research off of underpowered pilot samples undermines the validity of experimental psychological findings - and keeping pilot data away from peer review could do the same.
5. Citing papers that did not validate the manipulation. Manipulations are often asserted to be valid by citing a previously-published study that used the given manipulation. However, many of these cited papers did not themselves conduct a thorough validation process and therefore this citation approach leverages the assumed credibility of the published literature to imbue manipulations with unfounded validity. This practice is not unique to manipulation validation. For instance, state-level measures of affect often cite previous papers that failed to present validation evidence.
6. Altering manipulations without first validating the modified version. If an investigator wants to create a shorter version of a questionnaire, they must first go through a lengthy validation process of this new version of the scale. However, researchers can often modify an experimental manipulation (e.g., by swapping out stimuli, altering the instructions) without then having to re-validate this new version of the manipulation.
7. Applying a manipulation to a new context or population without first validating this new application. If a researcher wants to use a questionnaire in a new country, they must painstakingly translate the scale and then validate it in this new cultural environment. If they want to apply a measure developed for young adults to a population of older adults, they must first demonstrate similar psychometric properties with this older population. This same standard is not upheld with experimental manipulations, which are often administered to different populations and in widely-varying contexts (e.g., an online version of an in-lab manipulation) without first ensuring that the underlying validity of the manipulation is upheld.
8. Interacting 2+ manipulations (e.g., in a 2 x 2 factorial design) without first examining whether one invalidates the other(s). Context matters, that's the whole reason we do experimental manipulations in the first place. So it stands to reason that an experimental manipulation may potentially alter the meaning, efficacy, and therefore the validity of a subsequent manipulation. For instance, a recently-rejected participant may not pay as much attention to the instructions of a subsequently-complex manipulation, which may create experimental artifacts.
9. Testing the effect of a manipulation without knowing its typical duration. We often speak of manipulations as having 'an effect'. This is a fallacy as the effect of a manipulation varies as a function of time since its implementation. No manipulation's effect is infinite or unchanging. The strength of any manipulation will rise and fall, but without knowing the timecourse of the effect, it's questionable to say at any given timepoint in your study what effect you expect the manipulation to have.
10. Using 'boosters' without validating them first. Investigators sometimes seek to re-animate the effects of a manipulation by:
-re-administering an abbreviated version of the manipulation
-reminding participants of the manipulation
If boosters are used without having been validated beforehand, they might have unintended effects. A repeated administration or a reminder of the same manipulation may have a qualitatively different effect on participants than the initial manipulation. In such cases, the 'boosters' aren't boosting the original manipulation, but changing the meaning of it entirely.
11. When deception is employed, failing to estimate suspicion attrition rates. Experimental manipulations in psychology often involve deception of participants to avoid drawing participants' focus towards the study's hypotheses or to simulate an experience that isn't real. Papers are often all over the map on how they assess the number of participants who were suspicious of their deception (i.e., the suspicion attrition rate) or whether they assessed it all. Without knowing how many participants disbelieved your deception, it remains uncertain whether your procedures induced the desired psychological state in your participants.
So, how does one fix this situation and effectively validate an experimental manipulation?
A potential reason that psychology is in a so-called 'replication crisis' may be because we didn't spend sufficient resources, time, and energy on this validation phase of our manipulations.
Yet many experimental psychologists might disagree with me --- arguing that experimental manipulations are indeed validated. However, the current approach to the validation of experimental manipulations is undermined by several key issues:
1. An excessive or sole emphasis on face validity.
2. Use of unvalidated manipulation checks.
3. Assuming a manipulation is valid because it had the predicted effect on an outcome of interest.
***If you want more detail on these first three instances and my arguments for why they aren't good validation metrics, check out my previous blogpost on the topic.***
4. Using under-powered (and often unpublished) pilot studies. Many researchers do want to make sure their manipulations 'work' and to determine whether this is the case, they'll run pilot studies. These pilot studies are run-throughs of the manipulation alongside a manipulation check. They're often conducted with small samples in order to reserve greater resources for the real study of interest. The resulting pilot data often remain in laboratory file drawers, away from the scrutiny of peer review. Basing future experimental research off of underpowered pilot samples undermines the validity of experimental psychological findings - and keeping pilot data away from peer review could do the same.
5. Citing papers that did not validate the manipulation. Manipulations are often asserted to be valid by citing a previously-published study that used the given manipulation. However, many of these cited papers did not themselves conduct a thorough validation process and therefore this citation approach leverages the assumed credibility of the published literature to imbue manipulations with unfounded validity. This practice is not unique to manipulation validation. For instance, state-level measures of affect often cite previous papers that failed to present validation evidence.
6. Altering manipulations without first validating the modified version. If an investigator wants to create a shorter version of a questionnaire, they must first go through a lengthy validation process of this new version of the scale. However, researchers can often modify an experimental manipulation (e.g., by swapping out stimuli, altering the instructions) without then having to re-validate this new version of the manipulation.
7. Applying a manipulation to a new context or population without first validating this new application. If a researcher wants to use a questionnaire in a new country, they must painstakingly translate the scale and then validate it in this new cultural environment. If they want to apply a measure developed for young adults to a population of older adults, they must first demonstrate similar psychometric properties with this older population. This same standard is not upheld with experimental manipulations, which are often administered to different populations and in widely-varying contexts (e.g., an online version of an in-lab manipulation) without first ensuring that the underlying validity of the manipulation is upheld.
8. Interacting 2+ manipulations (e.g., in a 2 x 2 factorial design) without first examining whether one invalidates the other(s). Context matters, that's the whole reason we do experimental manipulations in the first place. So it stands to reason that an experimental manipulation may potentially alter the meaning, efficacy, and therefore the validity of a subsequent manipulation. For instance, a recently-rejected participant may not pay as much attention to the instructions of a subsequently-complex manipulation, which may create experimental artifacts.
9. Testing the effect of a manipulation without knowing its typical duration. We often speak of manipulations as having 'an effect'. This is a fallacy as the effect of a manipulation varies as a function of time since its implementation. No manipulation's effect is infinite or unchanging. The strength of any manipulation will rise and fall, but without knowing the timecourse of the effect, it's questionable to say at any given timepoint in your study what effect you expect the manipulation to have.
10. Using 'boosters' without validating them first. Investigators sometimes seek to re-animate the effects of a manipulation by:
-re-administering an abbreviated version of the manipulation
-reminding participants of the manipulation
If boosters are used without having been validated beforehand, they might have unintended effects. A repeated administration or a reminder of the same manipulation may have a qualitatively different effect on participants than the initial manipulation. In such cases, the 'boosters' aren't boosting the original manipulation, but changing the meaning of it entirely.
11. When deception is employed, failing to estimate suspicion attrition rates. Experimental manipulations in psychology often involve deception of participants to avoid drawing participants' focus towards the study's hypotheses or to simulate an experience that isn't real. Papers are often all over the map on how they assess the number of participants who were suspicious of their deception (i.e., the suspicion attrition rate) or whether they assessed it all. Without knowing how many participants disbelieved your deception, it remains uncertain whether your procedures induced the desired psychological state in your participants.
So, how does one fix this situation and effectively validate an experimental manipulation?
The Potential Solutions
To solve these problems we should discontinue the practices outlined above. But what then to put in their place? Fortuitously for experimental psychologists, we need not wander uncharted territories to learn how to validate our manipulations. We can just model our revolution on the validation procedures used for questionnaires.
1. Validate experimental manipulations prior to implementation (not alongside).
Researchers who seek to develop new self-report questionnaires or clinical assessments must often conduct (and publish) several validation studies before the scientific community adopts their measure. These efforts are summarized in 'validation papers' and are published in reputable journals dedicate to these projects (e.g., Assessment).
I argue that investigators should include and publish the results of this validation phase for new experimental manipulations. Instead of immediately applying a new manipulation to a focal hypothesis (e.g., social rejection increases political conservatism), several well-powered studies would first need to be run and scrutinized in order to estimate whether your manipulation exhibits empirical properties of construct validity (e.g., that your manipulation actually induces feelings of social rejection). These studies would then need to be subjected to the scrutiny of the peer review process.
Just as new questionnaires are published alongside an appendix that details the new measure, such manipulation validation studies would include a detailed step-by-step protocol of exactly how to implement the experimental procedure, including (but not limited to):
-how to randomize participants into each condition
-specifications about what testing environments should be used
-details about how testing rooms should be arranged
-scripts detailing exactly what experimenters should say to participants and when
-how experimenters/participants are blinded to condition
-training protocols for new research assistants
-quality checks to ensure that the study is being run appropriately
These protocols would be subject to the peer review process and could be posted publicly alongside any and all documentation, stimuli, and software code, in order to ensure that other labs can replicate the exact procedures. Other labs who seek to use the manipulation in their own work *must* then agree to adhere to the exact procedures outlined in the protocol, without deviation, in order to claim their use of the manipulation was valid. Badges could even be given to papers that demonstrated strict adherence to these standardized manipulation protocols.
This approach may entail a cultural shift towards a slower science. We are often eager to get right to the questions we want to answer, but this approach would require us to interject a laborious process between us and our desired hypothesis test. Taking the time to first stress-test our manipulations may be a frustrating-yet-necessary step towards increasing the credibility of experimental psychology.
This validate-then-implement approach would also potentially allow experimentalists to avoid the problems associated with employing manipulation checks in studies (e.g., drawing participants' attention to the true purpose of the manipulation). Once a manipulation has been validated, you could administer it without the manipulation checks - just as using a validated questionnaire doesn't then require that you also acquire an array of construct validation checks for that questionnaire.
Yet how do you demonstrate that your manipulation is valid in the first place? I turn to that next.
2. Map the nomological ripple of your manipulation.
The constructs we seek to experimentally-manipulate exist in a nomological network with other constructs. To say that our manipulation is valid, we must observe that it manipulates our construct of interest. However, by virtue of its nomological ties to other constructs, our manipulations will almost always simultaneously manipulate closely-related constructs to the one we seek to manipulate. However, if we have constructed a valid manipulation then the manipulation's effect should be strongest for the intended manipulation and progressively weaker on constructs that occupy related theoretical space. I refer to this diffusion of the manipulation effect through the nomological network as a nomological ripple and propose that it can be implemented as an empirical means of establishing the validity of your manipulation.
Manipulation validation studies could begin by articulating and depicting an abbreviated form of the nomological network around the construct they seek to manipulate (sample network depicted below). In this map, the core construct is depicted in the middle (Rejection), and nomologically-relate constructs could be depicted in concentric rings, with farther rings representing smaller expected ties to the core construct.
1. Validate experimental manipulations prior to implementation (not alongside).
Researchers who seek to develop new self-report questionnaires or clinical assessments must often conduct (and publish) several validation studies before the scientific community adopts their measure. These efforts are summarized in 'validation papers' and are published in reputable journals dedicate to these projects (e.g., Assessment).
I argue that investigators should include and publish the results of this validation phase for new experimental manipulations. Instead of immediately applying a new manipulation to a focal hypothesis (e.g., social rejection increases political conservatism), several well-powered studies would first need to be run and scrutinized in order to estimate whether your manipulation exhibits empirical properties of construct validity (e.g., that your manipulation actually induces feelings of social rejection). These studies would then need to be subjected to the scrutiny of the peer review process.
Just as new questionnaires are published alongside an appendix that details the new measure, such manipulation validation studies would include a detailed step-by-step protocol of exactly how to implement the experimental procedure, including (but not limited to):
-how to randomize participants into each condition
-specifications about what testing environments should be used
-details about how testing rooms should be arranged
-scripts detailing exactly what experimenters should say to participants and when
-how experimenters/participants are blinded to condition
-training protocols for new research assistants
-quality checks to ensure that the study is being run appropriately
These protocols would be subject to the peer review process and could be posted publicly alongside any and all documentation, stimuli, and software code, in order to ensure that other labs can replicate the exact procedures. Other labs who seek to use the manipulation in their own work *must* then agree to adhere to the exact procedures outlined in the protocol, without deviation, in order to claim their use of the manipulation was valid. Badges could even be given to papers that demonstrated strict adherence to these standardized manipulation protocols.
This approach may entail a cultural shift towards a slower science. We are often eager to get right to the questions we want to answer, but this approach would require us to interject a laborious process between us and our desired hypothesis test. Taking the time to first stress-test our manipulations may be a frustrating-yet-necessary step towards increasing the credibility of experimental psychology.
This validate-then-implement approach would also potentially allow experimentalists to avoid the problems associated with employing manipulation checks in studies (e.g., drawing participants' attention to the true purpose of the manipulation). Once a manipulation has been validated, you could administer it without the manipulation checks - just as using a validated questionnaire doesn't then require that you also acquire an array of construct validation checks for that questionnaire.
Yet how do you demonstrate that your manipulation is valid in the first place? I turn to that next.
2. Map the nomological ripple of your manipulation.
The constructs we seek to experimentally-manipulate exist in a nomological network with other constructs. To say that our manipulation is valid, we must observe that it manipulates our construct of interest. However, by virtue of its nomological ties to other constructs, our manipulations will almost always simultaneously manipulate closely-related constructs to the one we seek to manipulate. However, if we have constructed a valid manipulation then the manipulation's effect should be strongest for the intended manipulation and progressively weaker on constructs that occupy related theoretical space. I refer to this diffusion of the manipulation effect through the nomological network as a nomological ripple and propose that it can be implemented as an empirical means of establishing the validity of your manipulation.
Manipulation validation studies could begin by articulating and depicting an abbreviated form of the nomological network around the construct they seek to manipulate (sample network depicted below). In this map, the core construct is depicted in the middle (Rejection), and nomologically-relate constructs could be depicted in concentric rings, with farther rings representing smaller expected ties to the core construct.
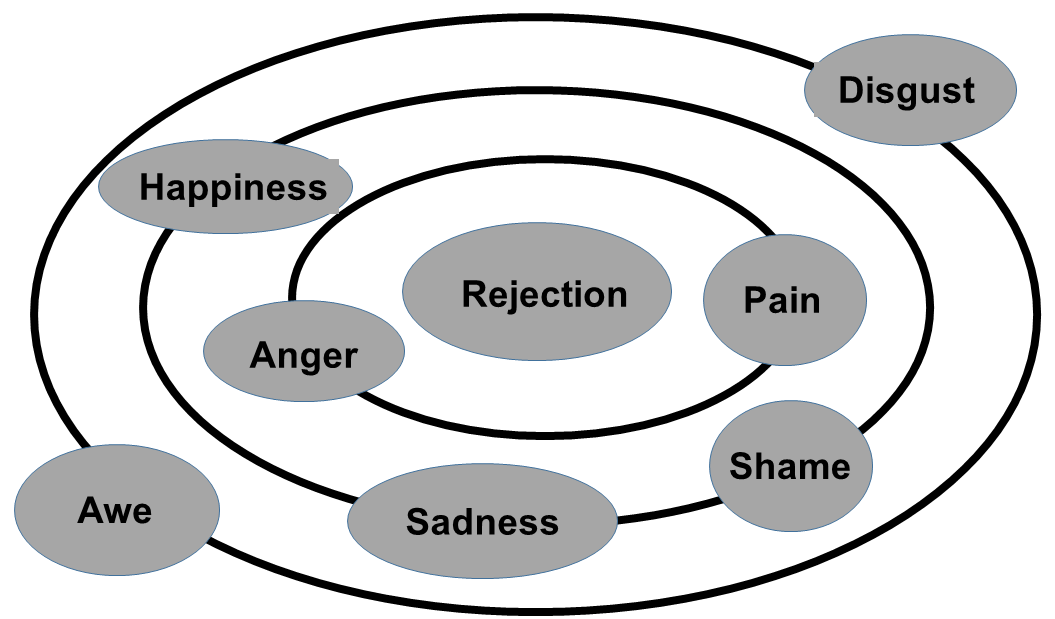
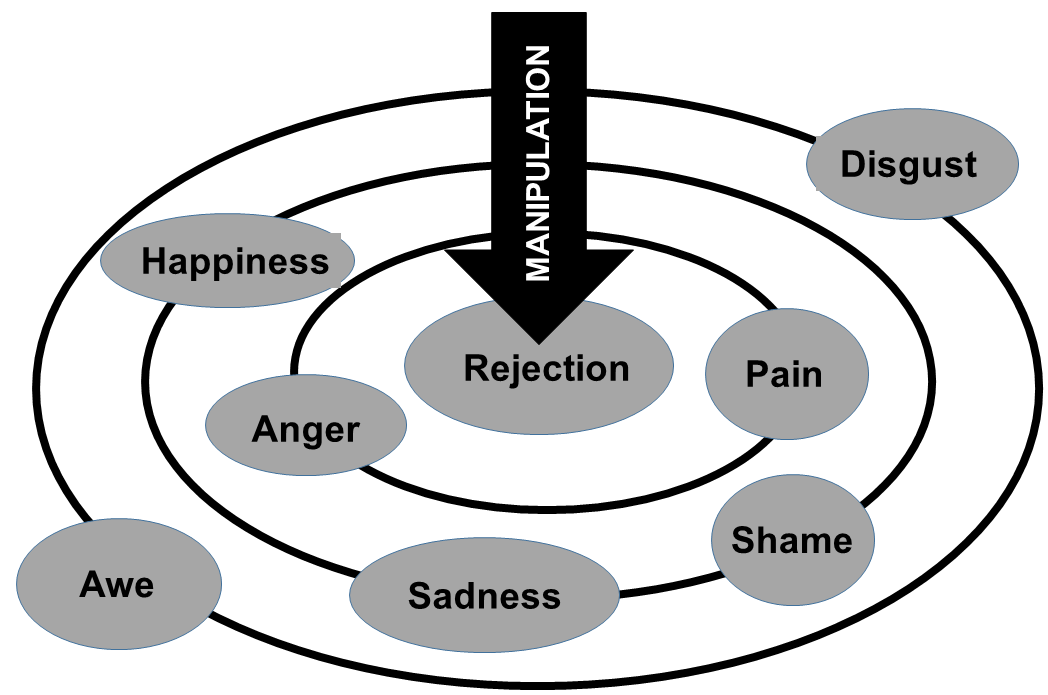
Constructs can be placed in relation to the core along a continuous radial gradient that reflects the strength of their correlation with the core construct (this can be obtained from existing literature). Stronger correlations (negative or positive) are placed closer to the core and weak to null correlations are set in the periphery. Each construct must be quantified by a validated measure thereof.
This nomological ripple can then be estimated by measuring each of the constructs in the network after the manipulation (in counterbalanced order) and plotting the corresponding effect size estimates (e.g., Cohen's d), as below [asterisks denote hypothetical statistical significance at p < .05].
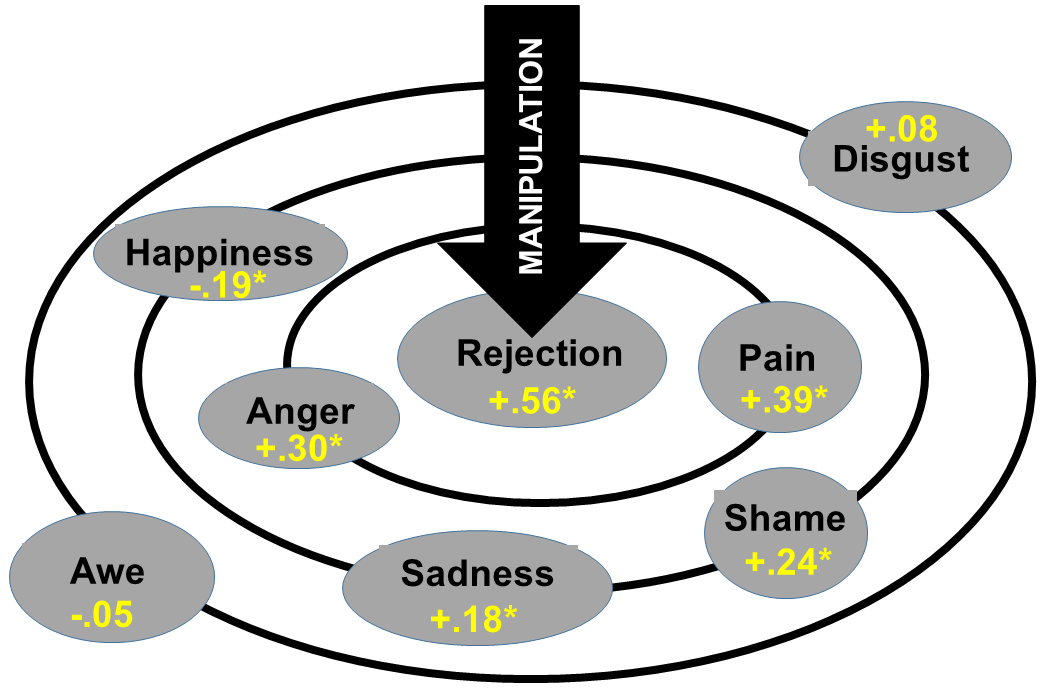
A valid manipulation should elicit the largest effect upon the core construct, with diminishing effect sizes at farther distances from the core. If your manipulation had a stronger effect on a construct outside the core (e.g., Anger), then your manipulation could be better characterized as a manipulation of that construct (e.g., an Anger Manipulation) than that of the intended target.
Ideally, the confidence intervals (or whatever estimate of uncertainty you deem wise) surrounding the manipulation's effect on the core construct should not overlap with any of the other effect intervals - as this will allow you to infer that your manipulation has a (somewhat) meaningfully larger effect on the core than on the distributed network.
Assuming you demonstrate an acceptable nomological ripple, the next question to answer is: how long does my manipulation effect last?
Ideally, the confidence intervals (or whatever estimate of uncertainty you deem wise) surrounding the manipulation's effect on the core construct should not overlap with any of the other effect intervals - as this will allow you to infer that your manipulation has a (somewhat) meaningfully larger effect on the core than on the distributed network.
Assuming you demonstrate an acceptable nomological ripple, the next question to answer is: how long does my manipulation effect last?
3. Plot the timecourse of your manipulation.
Test-retest validity doesn't really apply to manipulations in the same way that it applies to trait questionnaires, but time is still an important factor in determining the validity of a given experimental manipulation. The duration of your manipulation effect, and its effect-size at each timepoint, is crucial data to obtain in order to ensure that dependent measures are within the 'active' aspect of the manipulation effect's timecourse (i.e., when the manipulation is exerting its intended effect). Further, experimenters can identify temporal 'sweetspots' where the effect is strongest or most stable. We assume that the effect is strongest immediately and maintains stability for some fleeting period of time, but this may not always (or even often) be the case. Indeed, some psychological reactions take time to build (e.g., the growing horror that you got your socks wet in the morning and will now have wet socks for the entire day). Establishing the timecourse of a manipulation's effect allows us the precision to say how long the effect lasts, how stable it is over time, and how strong it is at given timepoints in our study.
To do so, investigators should provide baseline assessments of the target construct, administer the manipulation, and then repeat such measurements as rapidly as is logistically possible (assuming that the validity of the construct's measure is not undermined by fast and iterative assessment). The manipulation's effect size on each measure should then be depicted across these measurements and the temporal quirks should be described. Does the manipulation elicit a 'quick burn' (i.e., an immediate effect that decays quickly), as depicted below?
Test-retest validity doesn't really apply to manipulations in the same way that it applies to trait questionnaires, but time is still an important factor in determining the validity of a given experimental manipulation. The duration of your manipulation effect, and its effect-size at each timepoint, is crucial data to obtain in order to ensure that dependent measures are within the 'active' aspect of the manipulation effect's timecourse (i.e., when the manipulation is exerting its intended effect). Further, experimenters can identify temporal 'sweetspots' where the effect is strongest or most stable. We assume that the effect is strongest immediately and maintains stability for some fleeting period of time, but this may not always (or even often) be the case. Indeed, some psychological reactions take time to build (e.g., the growing horror that you got your socks wet in the morning and will now have wet socks for the entire day). Establishing the timecourse of a manipulation's effect allows us the precision to say how long the effect lasts, how stable it is over time, and how strong it is at given timepoints in our study.
To do so, investigators should provide baseline assessments of the target construct, administer the manipulation, and then repeat such measurements as rapidly as is logistically possible (assuming that the validity of the construct's measure is not undermined by fast and iterative assessment). The manipulation's effect size on each measure should then be depicted across these measurements and the temporal quirks should be described. Does the manipulation elicit a 'quick burn' (i.e., an immediate effect that decays quickly), as depicted below?
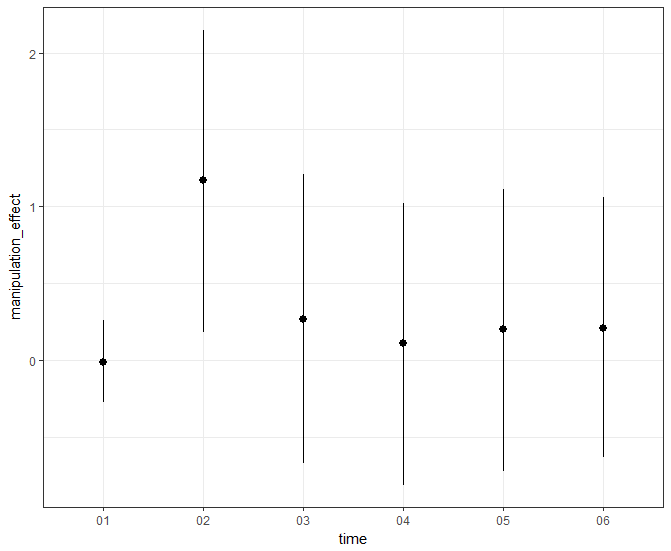
Or does your manipulation exhibit a 'slow burn' (i.e., a temporally-stable effect), as depicted below?
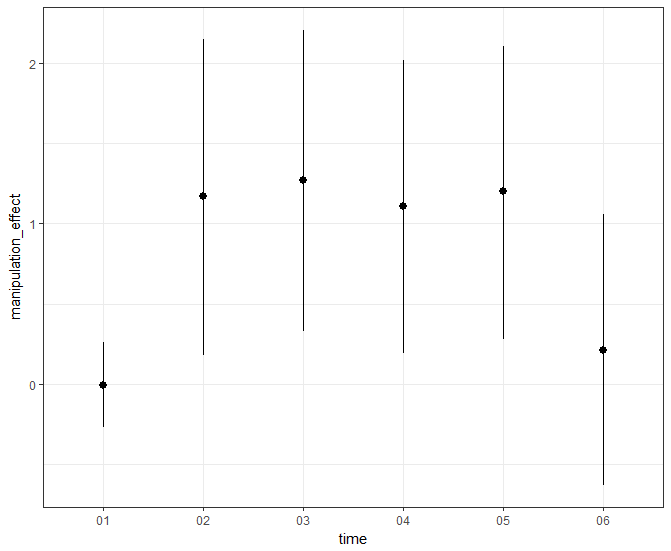
These depictions of your effect are crucial evidence for the temporal boundaries of your manipulation's construct validity, and for other reasons as well.
Depending on the construct you seek to manipulate, the timecourse of your manipulation may be critical information for research ethics boards. If there are concerns about participants leaving the lab in a potentially harmful or dangerous state, a carefully-estimated timecourse may allow you to predict the duration that participants will need to return to baseline.
This also means that if you seek to employ boosters to maintain the effects of an experimental manipulation over time, you should validate any boosters you employ after your manipulation and establish their individual timecourses.
Depending on the construct you seek to manipulate, the timecourse of your manipulation may be critical information for research ethics boards. If there are concerns about participants leaving the lab in a potentially harmful or dangerous state, a carefully-estimated timecourse may allow you to predict the duration that participants will need to return to baseline.
This also means that if you seek to employ boosters to maintain the effects of an experimental manipulation over time, you should validate any boosters you employ after your manipulation and establish their individual timecourses.
4. When deception is involved, estimate the suspicion attrition rate (SAR).
The construction of valid deception experiments emphasizes the need to minimize demand characteristics and subsequently, participant suspicion of your deception. However, such suspicion is not always empirically estimated and is certainly not estimated in a systematic and validated manner across laboratories.
To do so, investigators could administer a standardized suspicion probe (please someone make this, it would be one of the most cited instruments in psychology!) and report the rate of participants who express varying levels of disbelief in their deception (as depicted below).
The construction of valid deception experiments emphasizes the need to minimize demand characteristics and subsequently, participant suspicion of your deception. However, such suspicion is not always empirically estimated and is certainly not estimated in a systematic and validated manner across laboratories.
To do so, investigators could administer a standardized suspicion probe (please someone make this, it would be one of the most cited instruments in psychology!) and report the rate of participants who express varying levels of disbelief in their deception (as depicted below).
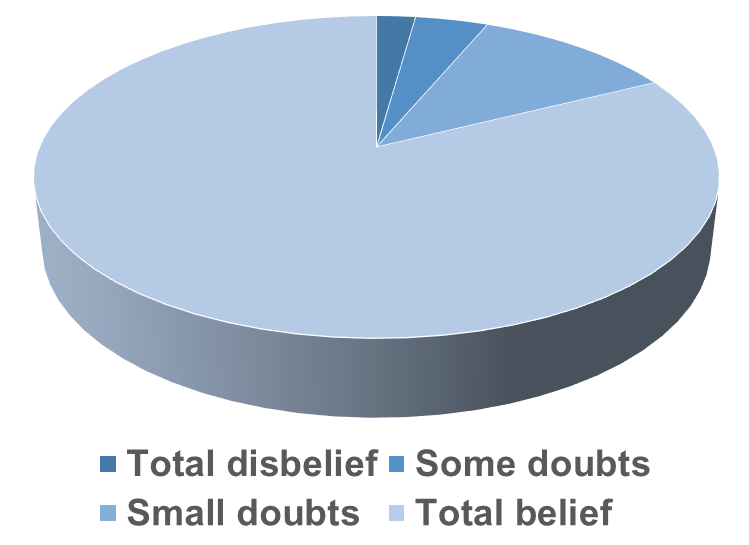
This data would allow researchers to optimize their manipulation to minimize suspicion. Further, creators of a new manipulation could suggest exclusion criteria based on the results of the suspicion probe (e.g., "Participants who report total disbelief or some doubts should be excluded from all analyses"). Such an exclusionary-cutoff could be based on data showing that the manipulation no longer exhibits construct validity at specific suspicion cutoffs.
Further, investigators could pair these suspicion assessments with measures of individual difference measures in order to examine whether those who are suspicious of their deception tend to exhibit specific attributes. Such information could help researchers understand if their manipulation incidentally induces suspicion among certain types of people (resulting in their potential exclusion from the sample), which could serve to undermine the validity of the manipulation.
Further, investigators could pair these suspicion assessments with measures of individual difference measures in order to examine whether those who are suspicious of their deception tend to exhibit specific attributes. Such information could help researchers understand if their manipulation incidentally induces suspicion among certain types of people (resulting in their potential exclusion from the sample), which could serve to undermine the validity of the manipulation.
Conclusion
Current manipulation validation practices aren't held to the same standard we apply to psychological measures, and this may have big costs for experimental psychology. I recommend some potentially controversial changes to the manipulation validation process that might improve the evidentiary value, replicability, and credibility of experimental psychology. Switching to a validation-first, implementation-later paradigm has already clearly worked for those developing psychological questionnaires, tests, and assessments. The results of such validation procedures can be published and presented on their own and such papers are often highly-cited. Further, using a truly valid manipulation will increase the replicability of your own work and lead to more credible bases for our understanding.
Post-Script | |
Over the course of thinking about this, I've noticed that what constitutes an experimental manipulation is far from clear. Check out the results of this twitter poll I ran:
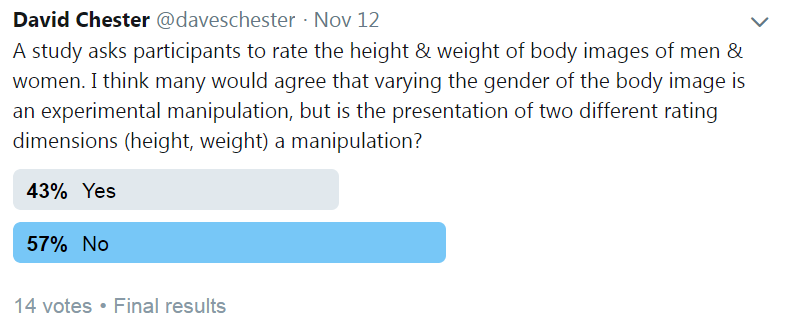
So perhaps the suggestions I provide above don't apply equally across all potential manipulations. If you're just presenting an array of measures, even if this meets strict experimental manipulation criteria, you probably don't need to validate this manipulation before you use it. But, if your manipulation is intended to induce a psychological state in your participants, then I think it must be validated before use in testing other hypotheses.
 RSS Feed
RSS Feed
